临床预测模型|1.预测模型的应用有哪些?
在之前的很多篇推送中,我们探讨了很多关于临床预测模型的内容。接下来,我们将结合统计大神Ewout W. Steyerberg的著作—Clinical Prediction Models, A Practical Approach to Development, Validation, and Updating,对临床预测模型的理论和实践进行系统的学习。
在这次的内容中,我们将系统了解预测模型在医疗领域中的应用。
预计阅读时间:26分钟。
医疗实践与研究
在公共卫生领域,预测模型可能有助于针对患病或患病风险相对较高的受试者进行预防性干预。在临床实践中,预测模型可以告知患者及其治疗医生诊断的概率或预后结果。在诊断性检查中,预测可能有助于估计一种疾病存在的概率。在研究中,预测模型可能有助于设计干预研究。在随机试验的分析中,调整基线风险。在观察性的研究中,预测模型也有助于控制混杂变量。
预测模型在公共卫生领域中的应用
增加预防性干预措施的针对性
预测模型可以预测人群中无症状受试者未来疾病的发生概率,例如众所周知的心血管疾病的弗雷明汉风险函数,其是当前多项预防性干预政策的基础。例如,他汀类药物治疗仅考虑用于心血管疾病风险相对较高的患者。同样,乳腺癌的预测模型也已开发出来,可以考虑对高风险人群进行更深入的筛查或化学预防。
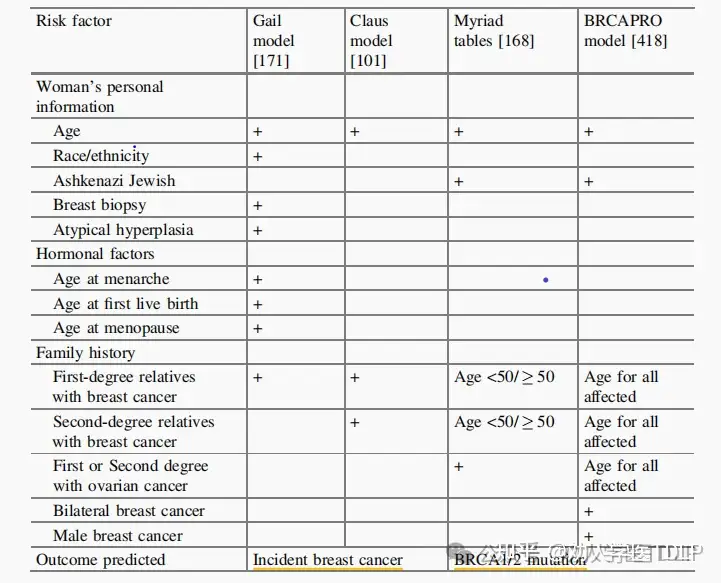
示例:乳腺癌预测模型
在1989年,Gail等人基于来自Breast Cancer Detection Demonstration Project(BCDDP)的病例对照数据,提出了著名的乳腺癌风险预测模型。BCDDP是美国国家癌症研究所(NCI)于1973年启动的一项大规模研究项目。该项目的目标是评估早期乳腺癌筛查的效果,以及使用乳房X线摄影术(即乳房X线照片,也称为乳房X光)进行早期乳腺癌筛查的可行性。
BCDDP的研究参与了约28万名女性,这些女性来自于30个不同的社区,并且在50岁至64岁之间。研究持续了6年,直到1979年。参与者被随机分配到两个组:一个接受乳房X线摄影术筛查的组,另一个是对照组,他们不接受筛查。这样设计是为了比较两组之间乳腺癌的发病率和死亡率。BCDDP的结果表明,接受乳房X线摄影术筛查的女性群体与未接受筛查的对照组相比,其乳腺癌的早期检测率有所增加,并且发现早期乳腺癌的女性死亡率较低。这些发现为乳腺癌筛查的推广提供了重要的科学证据,促进了早期诊断和治疗的实践。BCDDP为今后的乳腺癌筛查项目提供了基础,对于乳腺癌早期检测和治疗的重要性有着深远的影响。其他乳腺癌的风险预测模型还包括克劳斯模型(Claus Model)。Claus 模型以研究人员David J. D. Cunningham、Isaac D. Sasco、和Claus 和 Edward A. Cornwall 的名字命名。这个模型主要基于家族史,特别是家族中是否有一级亲属(母亲、姐妹或女儿)患有乳腺癌来预测个体患乳腺癌的风险。模型的基本假设是乳腺癌风险与家族史中患者的数量和关系的程度相关。一般来说,克劳斯模型根据患者家族中患有乳腺癌的亲属数量和患者年龄等因素,来估计患者未来发展乳腺癌的风险。具体而言,该模型可以根据家族史的情况将患者分为不同的风险组别,并给出相应的患病概率。与Gail模型不同,克劳斯模型需要输入一级或二级亲属乳腺癌确诊时的确切年龄。
一些乳腺癌是由乳腺癌易感基因(BRCA)突变引起的,称为遗传性乳腺癌。可疑的遗传性乳腺癌家族史包括许多乳腺癌和卵巢癌病例,或者家族成员中乳腺癌患者年龄在50岁以下。目前已经有简单的表格用于根据个人和家族史的特定特征来确定BRCA突变的风险。另一个模型更详细地考虑了家族史(BRCAPRO)。它明确使用家族中的遗传关系,因此被标记为孟德尔模型。计算基于贝叶斯定理。风险模型在乳腺癌中可能有两个主要作用:预测无症状女性的乳腺癌风险和预测BRCA基因突变的可能性。这些模型在预测因素方面有一些共同之处,当然也存在一些不同之处。有各种措施可以减少乳腺癌风险,包括行为干预(如锻炼、体重控制和饮酒)、预防性手术和医疗干预(如使用他莫昔芬)。
预测模型在临床实践中的应用
医疗决策支持
预测模型可能有助于估计潜在疾病的概率,以便我们进一步决策。当某种诊断的可能性极低时,通常无需进一步检查,而当诊断尚未充分确定以做出治疗决策时,可能需要进行更多检查。进一步的检查通常涉及一项或多项不完善的检查(灵敏度低于 100%,特异性低于 100%)。理想情况下,可以使用金标准检查(灵敏度 = 100%,特异性 = 100%)。然而在临床实践中,许多参考检查并不是真正的“金标准”,尽管它们被用作确定受试者是否患有该疾病的决定性指标。某些情况下,所谓的“金标准”可能不适合应用于所有怀疑患有该疾病的受试者,因为它可能对人体有害(例如侵入性检查)或者相当昂贵。
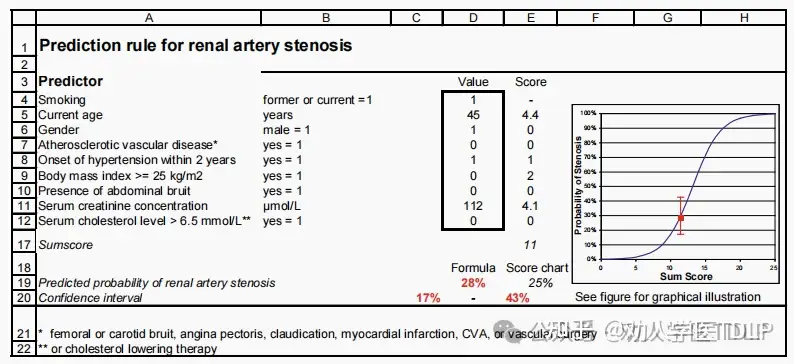
示例:肾动脉狭窄的预测模型
肾动脉狭窄是高血压的罕见原因。肾动脉造影是诊断肾动脉狭窄的金标准,是一种侵入性且花费较高的诊断性操作。既往有研究基于患者的临床特征开发了肾动脉狭窄的预测模型,用于选择进行肾血管造影的患者。对 477 名接受肾血管造影的高血压患者的数据进行逻辑回归分析。选择年龄、性别、动脉粥样硬化性血管疾病、近期高血压发病、吸烟史、体重指数、腹部血管杂音、血清肌酐浓度和血清胆固醇水平作为预测因子。回归模型的诊断准确性与肾血管造影的性能相似,敏感度为 72%,特异度为 90%。作者基于以上模型开发了一个交互式的 Excel 程序用于估计每个患者的肾动脉狭窄概率。下图显示了一个45岁男性近期发病的高血压的例子。该患者吸烟,无动脉粥样硬化性血管疾病的迹象,BMI<25,无腹部血管杂音,血清肌酐为112µmol/L,血清胆固醇正常。计算其总得分为11分,对应于狭窄的概率为25%。根据精确的逻辑回归计算,该概率为28% [95%置信区间17-43%]。
确定干预阈值
决策分析是一种权衡决策利弊的方法。对于在诊断工作完成后开始治疗的情况,一个关键概念是治疗门槛。该门槛被定义为治疗的预期益处等于避免治疗的预期益处的概率。如果诊断的概率低于门槛值,则首选不推荐治疗;如果诊断的概率高于门槛值,那么推荐治疗。门槛值由假阴性与假阳性决策的相对权重确定。如果假阳性决策远不如假阴性决策重要,则门槛值较低。例如,对于过度治疗的风险为0.1%,而正确治疗的好处为10%,意味着接近1%的门槛值(比例为1:100,门槛概率为0.99%)。另一方面,如果假阳性决策会带来严重的风险,则门槛值应该更高。例如,与过度治疗相关的伤害为1%,则门槛值为9.1%(比例为1:10)。门槛概念的进一步细节将在决策曲线评估预测模型性能时进行讨论。
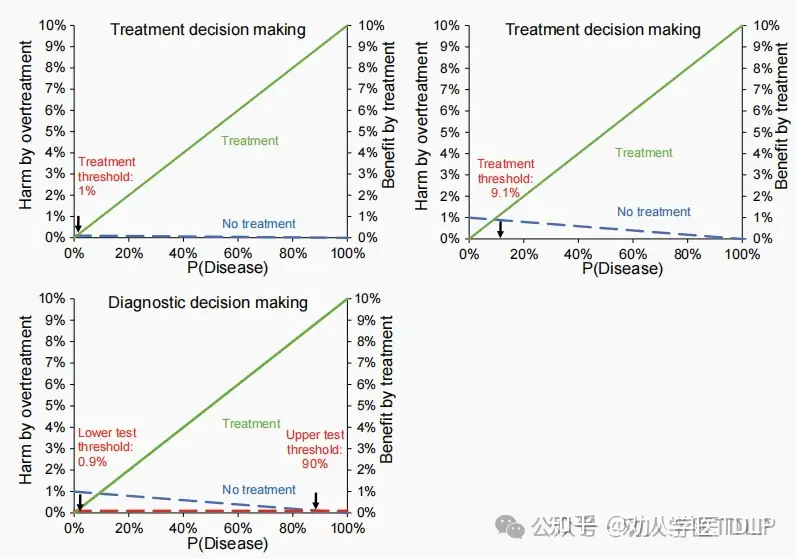
可以通过临床预测模型来估计疾病的概率。需要注意的是,只有当所有诊断检查(包括针对该疾病的所有可用检验)都完成时,才适用单一治疗阈值。如果仍然可以进行更多检验,则需要进行更复杂的决策分析以确定检查和治疗的最佳选择。然后我们有两个阈值:一个较低的阈值来识别那些没有接受治疗和没有接受进一步检查的患者;还有一个更高的阈值来确定谁将在没有进一步检查的情况下接受治疗。在这两者之间的是那些将受益于进一步检查的人。
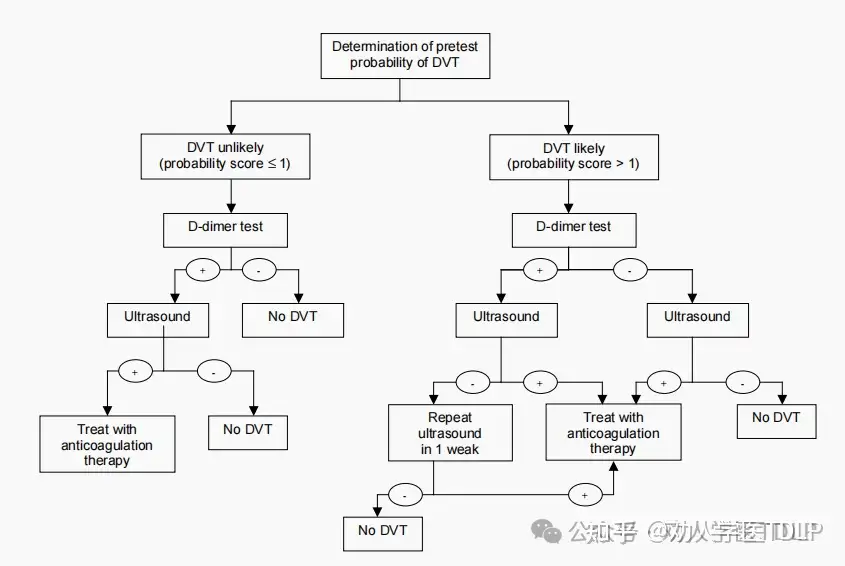
预测深静脉血栓
Wells临床预测规则结合了九个体征、症状和风险因素,将患者分为深静脉血栓(DVT)患病概率低、中等或高的类别。这个规则与单个特征相比可以更好地分层患者患有DVT的概率。对于低分险的患者(例如得分 ≤ 1),可以通过单独超声或血浆D-二聚体阴性结果排除DVT。对于DVT风险较高的患者(得分 > 1)的患者则需要同时超声检查和D-二聚体检查阴性才能排除DVT风险,其具体工作算法如下:
评估治疗强度
预后估计在确诊后指导决策也很重要。决策包括更高或更低强度的治疗方法。基于预后的决策框架与之前讨论的基于诊断概率的框架非常相似。只有在预期获得实质性收益的情况下,才应给予患者治疗,这种收益应超过任何风险和副作用。这方面的一个经典案例是抗凝剂使用和心房颤动的风险的关系。抗凝剂在降低非风湿性心房颤动患者中风风险方面非常有效。然而,使用这些药物会增加严重出血的风险。因此,在考虑治疗之前,中风的风险必须超过出血的风险。这两种风险可能取决于预测因子。类似的分析已经用于急性心肌梗死患者溶栓治疗的适应症。
示例:定义一个癌症预后不良的亚组
我们将高剂量化疗(HD-CT)作为一线治疗,以提高非精原细胞性睾丸癌患者的生存率。一些非随机试验报道,与标准剂量(SD)化疗(包括博莱霉素、依托泊苷和顺铂)相比,接受自体干细胞支持的一线治疗(包括依托泊苷、异环磷酰胺和顺铂)的患者生存率更高。然而,HD-CT与治疗期间(如粒细胞减少、贫血、恶心/呕吐和腹泻)、治疗后短期(如肺毒性)和治疗后长期(如白血病和心血管疾病)更严重的毒性发生相关。因此,HD-CT只适用于预后相对较差的患者。我们可以通过权衡预期的益处与危害来确定这种预后不良群体的阈值。HD-CT治疗的益处在于降低癌症死亡的绝对风险。如果我们假设处于最高风险的患者获益最大,那么益处随着癌症死亡风险呈线性增加。危害是由于治疗而导致治疗死亡的绝对风险增加(例如,与毒性相关)。假设治疗的毒性与预后无关,那么所有患者的危害水平相同。当患者的癌症死亡风险高于阈值时,即益处大于危害时,此时应该给予患者更为积极的治疗。
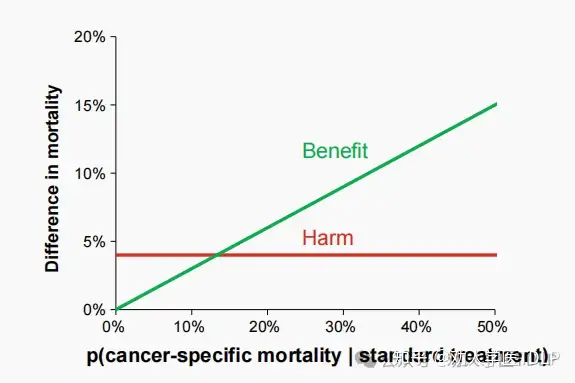
治疗的成本效益
治疗的成本效益直接取决于预后。如果收益很小(对于低风险的患者)和成本很高(例如,对所有患者产生相同的药物成本),那么治疗可能不具有成本效益。例如,他汀类药物治疗只适用于心血管风险增加的患者。而更积极的溶栓治疗只应用于那些有30天死亡风险增加的急性心肌梗死患者。可以发现许多其他的例子,假设治疗的相对益处在不同的风险群体中是恒定的,因此绝对收益随着风险的增加而增加。在上图中,我们假设伤害恒定,而获益与死亡风险相关。后者同时依赖于有效的预后模型与单一治疗的相对治疗效果。可以考虑对这种方法进行扩展,如果对更大的数据集进行建模,则具有更高的可靠性。具体来说,我们在患者亚组中寻找不同的治疗效果。然后放宽相对获益固定的假设:一些患者可能对某种治疗反应相对较好,而另一些则没有。年龄或特定疾病类型等患者特征可能与治疗反应相互作用。药物的作用可能被药物代谢影响,例如,由细胞色素 P450酶和药物转运蛋白介导。药物基因组学领域的研究人员旨在进一步了解个体患者的基因构成(基因型)与药物治疗反应之间的关系,以便更好地预测治疗反应。成本效益将根据治疗反应的不同可能性而有所不同。但应该注意的是,在没有生物学机制/原理的情况下,这种亚组效应很可能是虚假的。即使存在生物学机制/原理,也需要足够大的样本量来保证亚组分析的统计效能。这些远远超过了检测治疗的主效应所需的样本量。在最佳情况下,样本大小需要是四倍大才能检测到与主效应相同大小的交互作用。如果我们假设交互作用是主效应大小的一半,则需要16倍的样本量。
延迟治疗
在医疗实践中,预测模型可以为患者及其亲属提供信息,使他们对病程有现实的预期。有时可以采取保守的方法,即遵循疾病的自然史。例如,如果检测到“惰性”的前列腺癌,许多男性可能会选择观察等待策略。或者,如果女性具有相对有利的特征,她们可能会对怀孕机会感到放心。
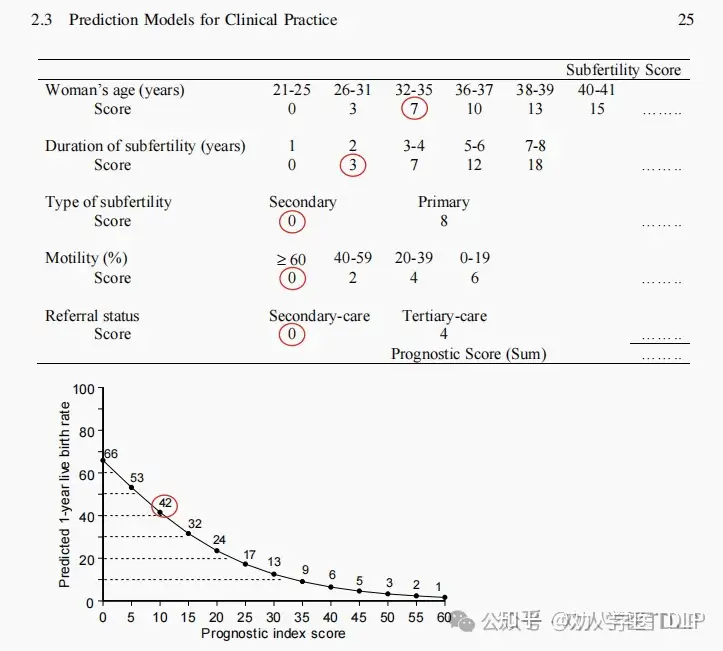
示例:自然怀孕的机会
根据三项预测不育夫妇自然妊娠的模型研究的数据,开发了一种“综合模型”,用于预测在随访1年内活产的自发受孕。这种综合模型比原始模型具有更广泛的经验基础。预测因素包括一些容易获得的特征,例如不孕持续时间、女性年龄、原发性或继发性不孕症、活动性精子的百分比,以及这对夫妇是由全科医生还是妇科医生转诊。使用该模型,可以很便捷地计算出一年内自然怀孕的概率。(首先计算预后分数。然后,预后分数对应于一个概率,可以从图表中读取)。
手术决策
在手术中,通常会采取短期风险来降低长期风险。短期风险包括并发症和死亡率。手术旨在减少自然病程中可能发生的长期风险。紧急情况下的手术包括创伤手术和动脉瘤破裂(动脉扩张)等疾病相关的手术。择期手术针对许多情况进行,即使对于这样有计划和准备充分的手术,短期风险和负担也绝不会为零。在肿瘤学中,手术风险增加通常会导致选择风险较低的治疗,例如化疗或放疗,或姑息治疗。例如,在许多癌症中,老年患者和合并症较多的患者较少接受手术。目前已经开发了许多预后模型来估计手术的短期风险,例如30天死亡率。这些模型的复杂性和准确性各不相同。此外,尽管很难找到不需要手术干预治疗适合疾病自然病程的患者群体,仍然有一些针对各种疾病长期风险的模型被开发。
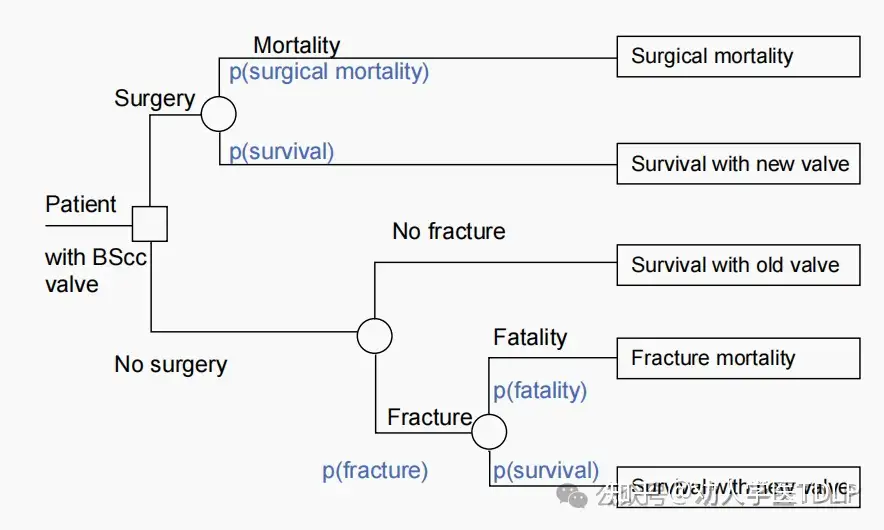
示例:有风险的心脏瓣膜置换的手术决策问题
Björk–Shiley convexo-concave (BScc) 机械心脏瓣膜在报告机械故障(出口支柱断裂)后于1986年退出市场。截至该产品退出市场时,全世界已经植入了大约86,000个BScc瓣膜。出口支柱突然断裂通常是致命的。因此,可以考虑用另一个更安全的瓣膜进行预防性置换,以避免断裂的风险。而决策分析是衡量因出口支柱断裂导致的长期预期寿命减少与短期手术死亡风险非常有用的方法。
出口支柱断裂风险导致的长期预期寿命损失取决于三个方面:(1)患者存活情况下,每年发生断裂的风险;(2)断裂的致死率;(3)年死亡风险(生存)。这种预期寿命的长期减少必须与手术死亡的风险进行权衡。
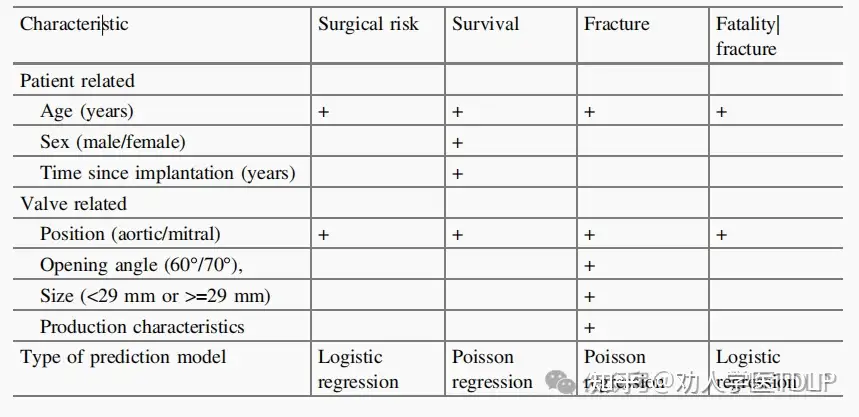
如果患者在手术中幸存下来,则假定断裂风险降至零。根据1979年至1985年间荷兰2,263名植入BScc瓣膜的患者的随访经验,考虑了随访期间发生的50例断裂和883例死亡患者(不包括断裂)。针对各个方面开发了预测回归模型。断裂风险是这个决策问题的关键因素。出现结局事件的患者样本量较少使得预测建模具有挑战性,预测模型的各个变量也需要关注。一个相对详细的模型包括四个传统预测因素,年龄、位置(主动脉/二尖瓣)、瓣膜类型(70°开角瓣膜的风险高于 60°瓣膜)和尺寸(瓣膜越大风险越高),以及两个生产特征。断裂的死亡率取决于患者的年龄和位置(主动脉位置的瓣膜死亡率更高)。存活率与年龄、性别、瓣膜位置和植入后时间有关。手术风险根据年龄和瓣膜位置进行建模。该决策分析的结果很大程度上取决于年龄:只有对于年轻患者才建议进行置换手术,因为他们手术风险较低,并且由于存活时间较长,骨折的长期影响更大。此外,瓣膜的位置会影响所有四个结局(手术风险、生存、断裂和死亡)。
预测模型在医学研究中的应用
在医学研究中,预测模型有以下用途。在实验研究中,比如随机对照试验,预后基线特征可能有助于患者的纳入和分层,并改善统计分析。在观察性研究中,充分控制混杂因素是至关重要的。
随机对照试验中的纳入和分层
在随机临床试验(RCTs)中,预后估计可用于选择研究对象。传统上,一组包含和排除标准被应用于定义RCT的研究对象。这些标准旨在根据预期结果创建更同质的群体。患者必须满足所有纳入标准,而非排除标准。或者,一些预后标准可以结合在预测模型中,根据个性化的预测进行选择。这会导致更精细的选择。在RCTs中,通常建议对主要预后因素进行分层。通过这种方式,试验组之间基线的预后得以被平衡。这有助于治疗结果的简单、直接比较,特别是对于较小的RCTs,可能更加容易出现一些基线不平衡。预后模型可以细化患者的这种分层,特别是当许多预后因素是已知的情况下。
示例:创伤性脑损伤的病例选择
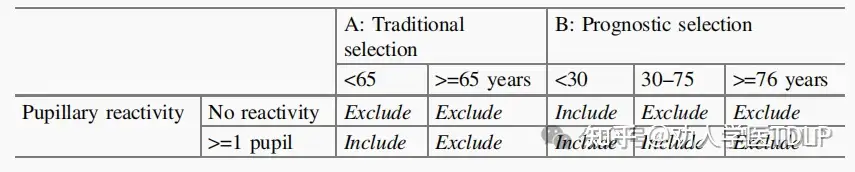
依据创伤性脑损伤的两个预测因子进行预后选择,在选择创伤性脑损伤 (TBI) 患者进行随机对照试验时。65 岁以上的患者和瞳孔无反应的患者常因预后很差而通常被排除在外。现实情况中,我们发现满足任一上述标准的患者在 6 个月的随访中死亡率高于 50%。因此,我们可以简单地只选择那些 65 岁以下且至少有一侧瞳孔反应的患者。
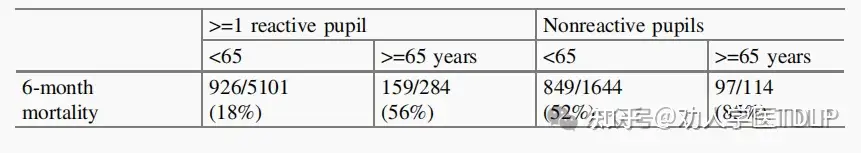
我们还可以基于单个指标使用预后模型来更有效地选择患者纳入研究。一个简单的回归模型中可以用“年龄”和“瞳孔反应”更详细地计算死亡概率。如果我们的目标是排除那些预测风险超过50%的患者,这将导致无任何瞳孔反应的患者的年龄限制为30岁,而有任何瞳孔反应的患者的年龄限制为76岁。因此,如果我们只想纳入那些死亡风险 <50% 的患者,则始终可以纳入30 岁以下的患者,并且如果至少有一侧瞳孔存在对光反射,则可以纳入65 至 75 岁之间的患者 。
RCT中的协变量调整
预测模型更重要的作用是在RCT分析中的预后基线特征的作用。随机化的优势在于,在观察到的和未观察到的基线特征方面,在治疗组之间产生了可比性。因此,在RCT中不会出现系统的混杂因素。但是一些观察到的基线特征可能与结局密切相关。对这种协变量进行调整有几个优点:
==减少组间随机不平衡造成的治疗效果估计中的任何失真==
==增加检测治疗效果的统计效能==
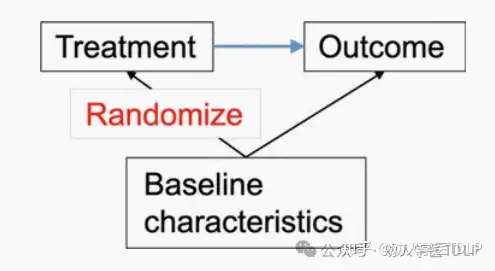

对于随机临床试验,随机化保证估计治疗效果的偏倚先验为零,不会因观察到或未观察到的基线特征而失真。然而,可能会出现随机不平衡,产生这样的问题:如果两组完全平衡,治疗效果会怎样?我们可能认为这种扭曲是一种后验偏移,因为它影响解释的方式与观察流行病学研究类似。
回归分析可以纠正这种随机不平衡。当回归模型中考虑的预测变量没有发生不平衡时,调整后和未调整的治疗效果估计值预计将相同。线性回归分析中确实如此。值得注意的是,在逻辑回归等广义线性模型中,即使预测变量完全平衡,调整后和未调整的治疗效果估计值也不同。调整后的效果预计将进一步远离零(中性值,OR进一步远离1)。这种现象被称为效应估计的“不可折叠性”,或“分层效应”。线性回归不会发生这种情况。
通过线性回归,对重要预测变量的调整可以提高估计治疗效果的准确性,因为结局的部分方差是由预测变量解释的。相反,在逻辑回归等广义线性模型中,治疗效果的标准误差总是随着调整而增加。在线性回归中,调整分析为治疗效果分析提供了更多依据,因为治疗效果的标准误差更小。对于逻辑回归等广义线性模型,调整对效能的影响并不明确。然而,已证明治疗效果估计的预期值增加超过标准误差。因此,与未调整的分析相比,调整后的逻辑回归分析中检测治疗效果的效能更高,类似于线性回归模型。
通过协变量调整来增加效能
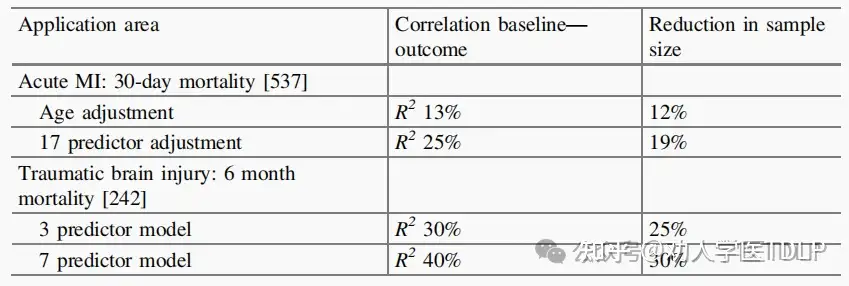
协变量调整导致的效能增加取决于基线协变量(预测因子)和结局之间的相关性。对于连续性结局,这种相关性可以用Pearson相关系数(r)来表示。样本量可以减少 1−r2,以通过协变量调整分析获得与未调整分析相同的统计效能 。非常强的预测变量可能具有 r = 0.7 (r2 =50%),例如血压等重复测量的基线协变量或问卷分数。所需的患者数量大约减少一半。r = 0.3 时节省不到 10% (r2= 9%)。在二分类结局的实证评估中也得到了类似的结果,其中Nagelkerke’s R2被用来表示预测因子和结局之间的相关性。在急性心肌梗死患者和脑外伤患者的死亡率模拟中,样本量的减少略小于1-R2。
示例:GUSTO-III 试验分析
GUSTO-III试验主要纳入急性心肌梗死患者。主要结局是30天死亡率。该试验预先指定了一个预后模型对干预效果进行初步分析。该模型结合了年龄、收缩压、Killip分级、心率、梗死位置和年龄与Killip分级的交互作用。在之前的GUSTO-I 试验中发现这些预测因子包含了30 天死亡率模型的 90% 的预后信息。如上所述,有相当多的理由可以更广泛地使用这种协变量调整。
观察性研究中的预测模型
观察性研究的主要目的是估计因果效应。混杂因素是观察性研究的流行病学分析中主要关注的问题。当比较治疗时,由于缺乏随机化,各组之间的基线信息通常参差不齐。具有特定特征的受试者比其他受试者更有可能接受某种治疗(“指示混淆”)。如果这些特征也影响结局,则治疗效果的直接比较是有偏移的,并且可能仅仅反映缺乏基线可比性(“混杂”)。除了治疗之外,还可以研究其他因素的病因学影响。通常来说,当随机化不可能时,若观察性研究是唯一可行的设计。处理混杂因素是此类分析中的一个重要步骤。回归分析是控制治疗组之间基线不平衡的常用方法,例如逻辑回归或 Cox 回归 。许多基线特征可以同时调整。与随机对照试验相反,我们只能平衡观察到的基线特征,理想情况下没有测量误差。我们应该特别担心任何未知的协变量,这些协变量可能会因与治疗选择和结局的关联而成为混杂因素。
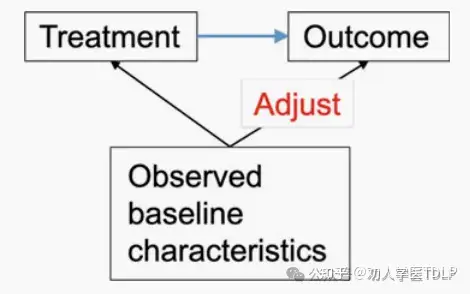
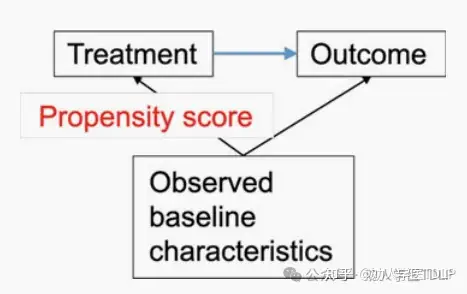
倾向性评分
当结局相对罕见时,用回归分析进行调整就会出现问题。这可能会导致调整分析中组间差异的估计存在偏差且效率低下。另一种方法是使用倾向评分,这在上面的情况中特别适用。倾向性评分定义了在给定一组混杂因素的情况下受试者接受特定治疗(“Tx”)的概率:p(Tx | 混杂因素)。为了计算倾向性评分,通常在逻辑回归模型中使用混杂因素来预测治疗,而不包括治疗结局。随后,倾向性得分在第二阶段用作汇总混杂因素。第二阶段的常见方法是倾向性评分匹配、倾向性评分分层(通常按四分位数)以及将倾向性评分与治疗纳入结局回归模型中。实证比较表明倾向性评分方法并没有优于传统的回归分析。相比之下,模拟研究表明,相对于混杂因素的数量,在结局很少的情况下,倾向性得分对于研究有一定益处。
示例:他汀类药物治疗效果
他汀类药物对急性心肌梗死(AMI)发生的影响已在随机对照试验和观察性研究中进行了研究。对1994年至1998年期间任何时候记录的LDL>为130mg/dl的社区健康计划成员进行倾向性评分分析。使用倾向性得分匹配开始使用他汀类药物治疗的患者和未开始他汀类药物治疗的患者。倾向评分预测了开始使用他汀类药物的概率。采用包含52个变量和6个二次项的logistic回归模型估计得分。开始使用他汀类药物患者与具有相似接受治疗倾向的未开始使用他汀类药物患者匹配(倾向误差在 0.01 以内)。找不到合适的匹配对象的患者将会被排除。在 4144 个使用他汀类药物患者中留下了 2901 个(70%)。4144 名患者的已知冠心病危险因素的患病率高于不匹配的未开始使用他汀类药物的患者。对这些未匹配队列的随访发现,启动他汀类药物治疗的患者中有325例AMI,未启动的患者中有124例AMI(风险比 2.1)。倾向性得分匹配队列 (n = 2901) 在 52 个匹配基线特征中有51个特征非常相似。开始使用他汀类药的患者中有 77 例 AMI,而匹配的未开始他汀治疗的患者中有 114 例发生 AMI(风险比 0.69)。作者得出的结论是,该社区健康计划的成员使用他汀类药物有利于 AMI 的发生,但需要警示的是,不属于模型部分的预测因子可能在倾向性评分匹配的队列之间保持不平衡,从而导致残余混杂。

不同数据来源的比较
预测模型的另一个应用领域是比较不同医院(或其他护理提供者)的结局。医疗保健提供者的质量是根据其结局进行比较的,这些结局被视为绩效指标。提供者之间的简单比较显然可能会因病例组合的差异而产生偏移,例如,学术中心可能会看到更严重的患者,这导致患者整体结局较差。在这种比较中需要预测模型来进行案例组合调整。另一个问题是提供的单位可能较小并且进行了多次比较。
总结
总之,预测模型的潜在应用领域,包括公共卫生(预防干预的目标)、临床实践(诊断检查、治疗决策、共同决策)和医疗研究(随机对照试验的设计和分析) ,观察性研究中的混杂因素调整)。从模型中获取预测必须与深入了解疾病机制和病理生理过程分开。
供稿:圆圆
编排:Roger不言